Ahol az informatika és a nyelv összeér
Milyen informatikával és nyelvvel kapcsolatos kutatások folynak a Karon?
– Elsősorban írott szövegekkel foglalkozunk, de a hagyományos szoftverektől eltérően mi nem betűkben, hanem tartalmakban gondolkodunk. Karunkon működik egy akadémiai kutatócsoport is, amelynek az analitikus grammatika – röviden: AnaGramma – nevű projektje pontosan illeszkedik a kari küldetésnyilatkozatban megfogalmazott emberközpontú informatikához, egy másik csoport pedig elsősorban a nyelvtechnológia orvosbiológiai alkalmazásaival kapcsolatos kutatásokkal foglalkozik.
Milyen új megközelítést tesznek lehetővé az önök nyelvtechnológiai kutatásai?
– Az MTA–PPKE kutatócsoportban az emberi információfeldolgozás ismert részeit próbáljuk meg összekapcsolni a nyelvtechnológiában elért eddigi eredményeinkkel, eszközeinkkel. A kutatás célja egy olyan nyelvi értelmezőrendszer megvalósítása, amely nem úgy működik, mint egy tipikus számítógép, hanem úgy, ahogy egy tipikus ember, azaz nem téved ott, ahol az ember sem téved. A magyar nyelvű szövegekből kiindulva egy komplex reprezentáció létrehozásán dolgozunk, amelynek segítségével olyan kérdésre is képes lesz a rendszer válaszolni, ami szó szerint nem is volt benne az eredetiben.
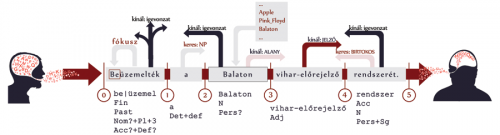 A ‚Beüzemelték a Balaton vihar-előrejelző rendszerét.’ mondat elemzése az AnaGramma rendszerben
A ‚Beüzemelték a Balaton vihar-előrejelző rendszerét.’ mondat elemzése az AnaGramma rendszerbenAz ember minden szónak éppen azt az értelmét választja ki, ami akkor és ott helyes. Olyan feldolgozást próbálunk tehát létrehozni, amely az emberhez hasonlóan kiszűri azt, ami nem lehetséges az adott szövegkörnyezetben. Míg a nyelvészek többsége elsősorban egy mondat szerkezetével, addig mi egy nagyobb egységgel, egy megnyilvánulással foglalkozunk egyszerre. Úgy gondoljuk, hogy az igazi elemzés az, ami az emberi információfeldolgozás algoritmusaival történik. Ezt kutatjuk, ugyanis a pszicholingvisztika eredményeit viszonylag ritkán ültetik át a számítógépes gyakorlatba. A projektet egyébként egy év múlva fejezzük be, akkor bemutatjuk, hogy egy ezeken az elveken nyugvó és viszonylag gazdag magyar nyelvi ismerettel rendelkező rendszer milyen módon működik.
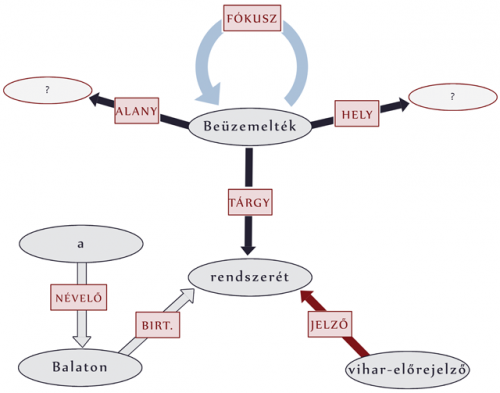 A példamondat belső reprezentációja az AnaGramma rendszerben
A példamondat belső reprezentációja az AnaGramma rendszerbenÉs mi a másik projekt, a Digitális konzílium célja?
– Bár egyetlen nyelvi rendszer él bennünk, de ezt sokféle módon tudjuk az adott helyzetekhez adaptálni. Vannak azonban olyan területek az életben, ahol nem ismerjük eléggé a szabályokat, mert nem pontosan formázott a szöveg, és számunkra sok „titkos kód” is megjelenik benne: ilyen például az orvosi leletek, a kórházi zárójelentések világa. Gyakran nem érti a beteg, amit az orvosa leír, mert félig-meddig latinul, angolul van, ráadásul tele van ismeretlen rövidítésekkel és olykor elütésekkel is. Az orvos és az asszisztens viszont pontosan tudja, mi van oda írva. Vagyis létezik egy kódértelmezés, csak az a kérdés, hogy milyen további tudás kell hozzá, amitől bárki számára értelmezhetővé válik a szöveg. A Semmelweis Egyetemmel együttműködve az orvosoktól igyekeztünk megszerezni azt az alapvető tudást, amely ahhoz kell, hogy létre tudjunk hozni egy olyan számítógépes rendszert, amely képes értelmezni ezeket a szövegeket. A távlati cél az, hogy egy orvos akkor is konzíliumot tarthasson más kollégákkal, ha azok időben, térben esetleg nincsenek is jelen. Ha van egy olyan eset, amiről az orvos meg szeretné tudni például, hogy mások milyen kezelést alkalmaztak, akkor ennek a rendszernek a segítségével megjelennek a hasonló leletek a számítógépén, függetlenül attól, hogy azok milyen egyedi rövidítésekkel – sőt akár attól is, hogy milyen nyelven – lettek eredetileg leírva.
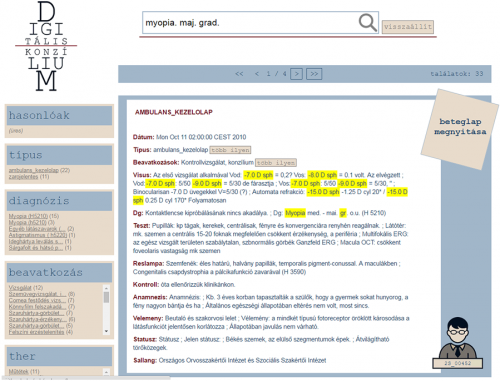 A Digitális Konzílium lekérdező felülete
A Digitális Konzílium lekérdező felületeHol tartanak most a kutatásban?
– Szemészeti zárójelentéseket már elég jól elemzünk. Ezt a projektet a Pázmány Egyetem támogatja, a korábban említett, a nyelv pszichológiája által motivált számítógépes elemzést pedig az MTA. Ez utóbbi keretében kutatásunk egyfajta „melléktermékeként” felépítettük a magyar nyelv legnagyobb szövegkorpuszát, amely minden szóhoz tartalmazza a szófaját és szóalaktani tulajdonságait, valamint a főnévi csoportok határai is be vannak jelölve.
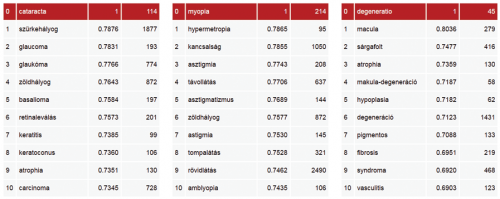 Géppel előállított fogalmi csoportok az orvosi korpuszból
Géppel előállított fogalmi csoportok az orvosi korpuszbólMéretei világviszonylatban is komolyak: 1,2 milliárd szóból áll, 290 millió főnévi szerkezetet és mintegy 67 millió magyar mondatot tartalmaz: ez a Pázmány Korpusz.•